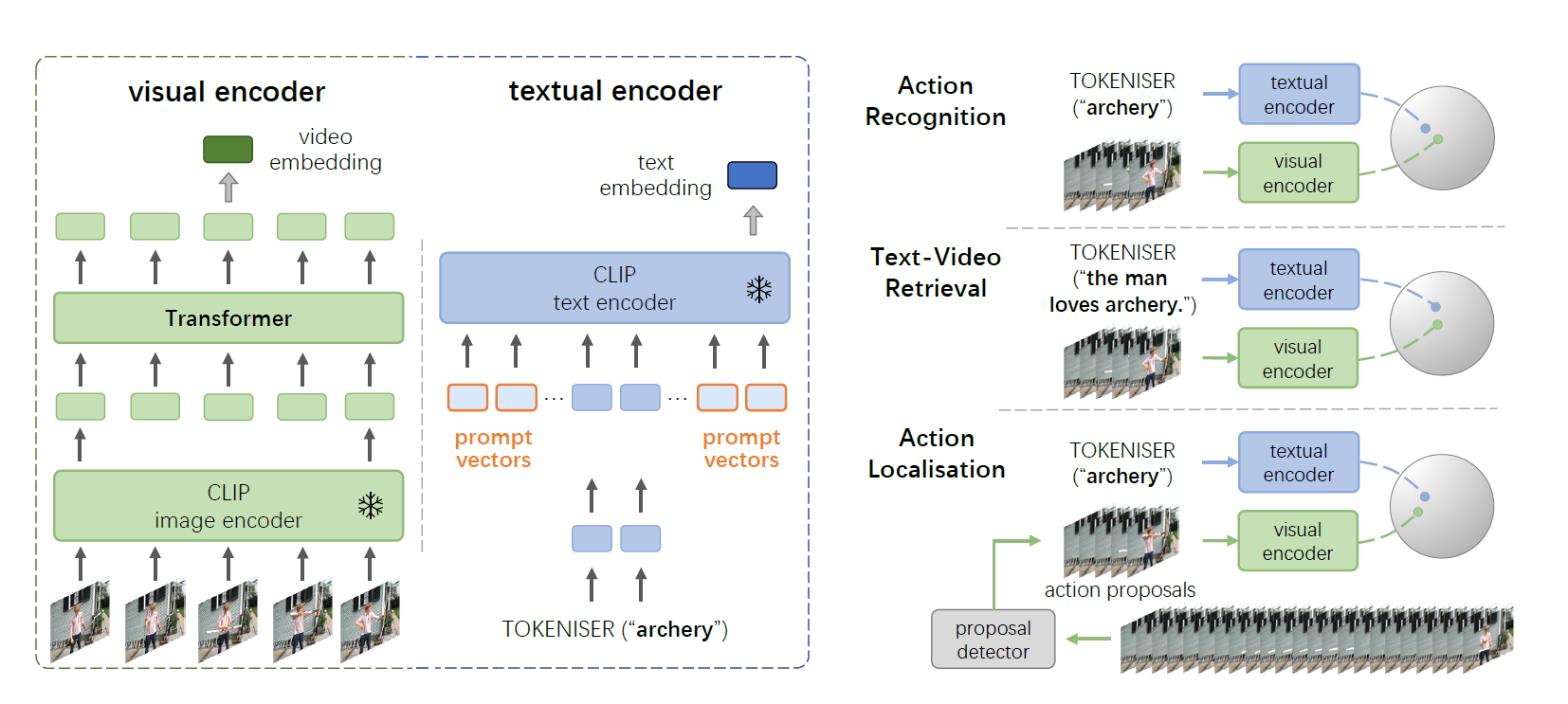
Hypergraph Transformer
摘要
骨架基础的动作识别旨在给定人体关节坐标及其骨架互连来识别人类动作。通过将关节定义为顶点,其自然连接定义为边,先前的工作成功地采用了图卷积网络(GCN)来建模关节的共现,并获得了出色的性能。更近期,发现了GCN的一个限制,即拓扑结构在训练后是固定的。为了放松这种限制,采用了自注意力(SA)机制使GCN的拓扑结构对输入变得自适应,产生了目前最好的混合模型。同时,也尝试了简单的Transformer,但由于缺乏结构先验,它们仍落后于目前最好的基于GCN的方法。与混合模型不同,我们提出了一种更优雅的方法,通过图距离嵌入将骨连接性结构融入Transformer。我们的嵌入在训练期间保留了骨架结构的信息,而GCN仅将其用于初始化。更重要的是,我们揭示了图模型通常存在的一个潜在问题,即成对聚合从本质上忽略了身体关节之间的高阶运动依赖性。为弥补这一空白,我们在超图上提出了一种新的自注意力(SA)机制,称为超图自注意力(HyperSA),以融入内在的高阶关系。我们将结果模型称为Hyperformer,它在NTU RGB+D、NTU RGB+D 120和Northwestern-UCLA数据集上都优于目前最好的图模型,在精度和效率方面。