SkateFormer
看latex像是投eccv,目前代码未公布,但点出奇的高。
摘要
基于骨骼数据的动作识别是一种根据关节坐标及其在骨骼数据中的连接性对人类动作进行分类的技术,在各种场景中被广泛应用。虽然图卷积网络(GCNs)已被提出用于表示为图的骨骼数据,但它们受到关节连接性限制的有限感受野的影响。为了解决这一限制,最近的进展引入了基于Transformer的方法。然而,捕获所有帧中所有关节之间的相关性需要大量的内存资源。为了缓解这一问题,我们提出了一种称为Skeletal-Temporal Transformer(SkateFormer)的新方法,它根据不同类型的骨骼-时间关系(Skate-Type)对关节和帧进行划分,并在每个分区内执行骨骼-时间自注意力(Skate-MSA)。我们将用于动作识别的关键骨骼-时间关系分类为四种不同类型。这些类型结合了(i)基于物理上相邻和远离的关节的两种骨骼关系类型,以及(ii)基于相邻和远离帧的两种时间关系类型。通过这种分区特定的注意力策略,我们的SkateFormer可以以高效的计算方式选择性地关注对动作识别至关重要的关节和帧。在各种基准数据集上进行的广泛实验证明我们的SkateFormer优于最近的最先进方法。
引言
现有Transformer方法的问题
利用自注意力来捕获所有关节对之间关系的基于Transformer的方法可以用于缓解难以有效地捕获远距离关节之间关系的问题。考虑每个帧中的每个关节是低效的,因为某些帧中的特定关节对于特定的动作识别更为关键。 如Skeletr尝试通过在进行自注意力之前沿关节或帧维度压缩特征; 如STST, DSTA, STTR, fgstformer, Hyperformer等仅使用骨骼或时间关系; 如IGFormer,ISTA-Net等通过对物理上相似的骨骼信息进行tokenize,从而减少计算复杂度
解决方案
提出了一种高效的基于Transformer的方法,称为Skeletal-Temporal Transformer(SkateFormer),引入了关节和帧分区策略以及基于骨骼-时间关系类型(Skate-Type)的分区特定自注意力。
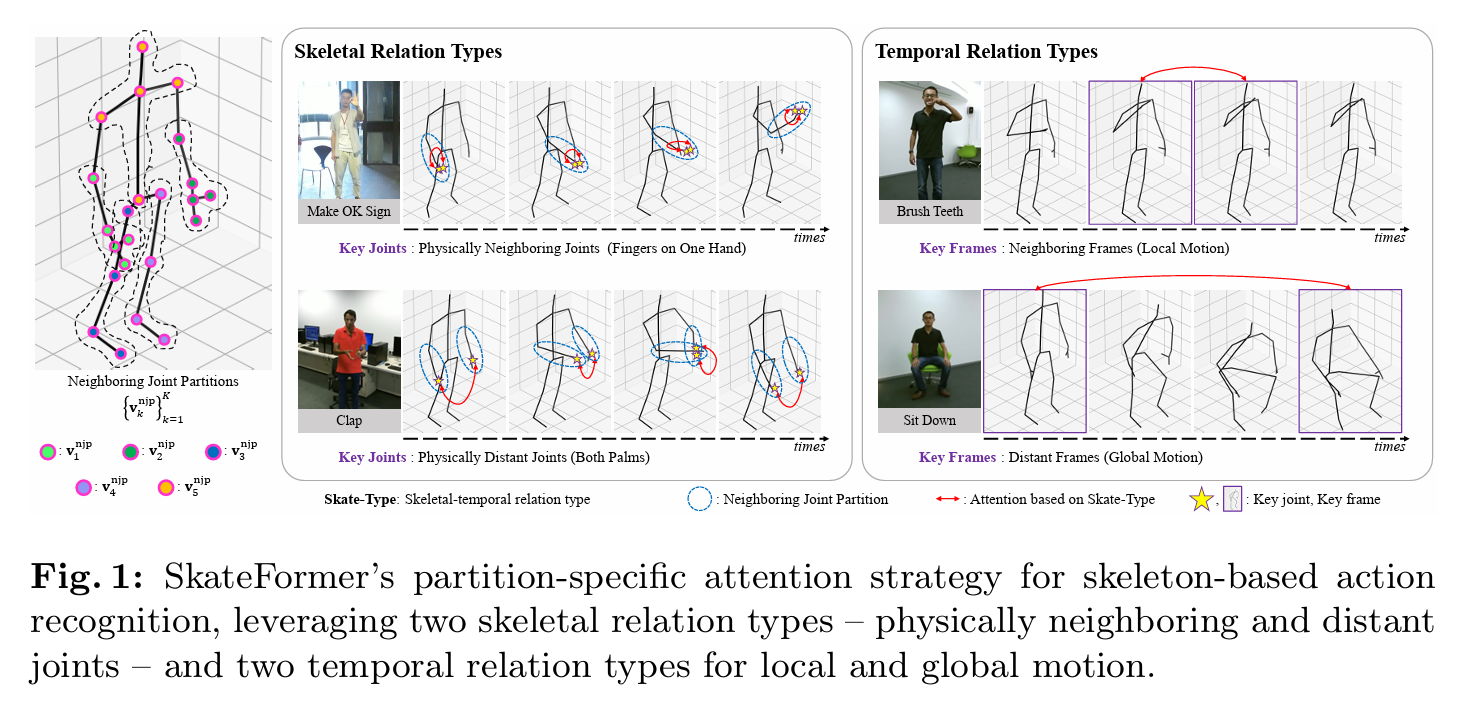 上图给出了SkateFormer的关节和帧分区策略以及分区特定自注意力。例如,在“做OK手势”动作类中,物理上相邻关节之间的关系(例如,同一只手上的关节)至关重要,而在“鼓掌”动作类中,物理上相隔较远的关节之间的关系(例如,两只手掌之间)更为关键。就时间关系而言,对于像“刷牙”类中的重复局部运动,相邻帧之间的关系至关重要,而对于像“坐下”这样的全局运动,远距离帧之间的关系变得至关重要。此外,动作执行的速度可能会根据演员而有显著差异。
上图给出了SkateFormer的关节和帧分区策略以及分区特定自注意力。例如,在“做OK手势”动作类中,物理上相邻关节之间的关系(例如,同一只手上的关节)至关重要,而在“鼓掌”动作类中,物理上相隔较远的关节之间的关系(例如,两只手掌之间)更为关键。就时间关系而言,对于像“刷牙”类中的重复局部运动,相邻帧之间的关系至关重要,而对于像“坐下”这样的全局运动,远距离帧之间的关系变得至关重要。此外,动作执行的速度可能会根据演员而有显著差异。
引入了一种新颖的分区特定注意力(Skate-MSA)。将骨骼-时间关系划分为四种分区类型:(i)相邻关节和局部运动 -- Skate-Type-1,(ii)远距离关节和局部运动 -- Skate-Type-2,(iii)相邻关节和全局运动 -- Skate-Type-3,以及(iv)远距离关节和全局运动 -- Skate-Type-4。
Contribution
We propose a Skeletal-Temporal Transformer (SkateFormer), a partition-specific attention strategy (Skate-MSA) for skeleton-based action recognition that captures skeletal-temporal relations and reduces computational complexity.
We introduce a range of augmentation techniques and an effective positional embedding method, named Skate-Embedding, which combines skeletal and temporal features. This method significantly enhances action recognition performance by forming an outer product between learnable skeletal features and fixed temporal index features.
Our SkateFormer sets a new state-of-the-art for action recognition performance across multiple modalities (4-ensemble condition) and single modalities (joint, bone, joint motion, bone motion), showing notable improvement over the most recent state-of-the-art methods. Additionally, it concurrently establishes a new state-of-the-art in interaction recognition, a sub-field of action recognition.
方法
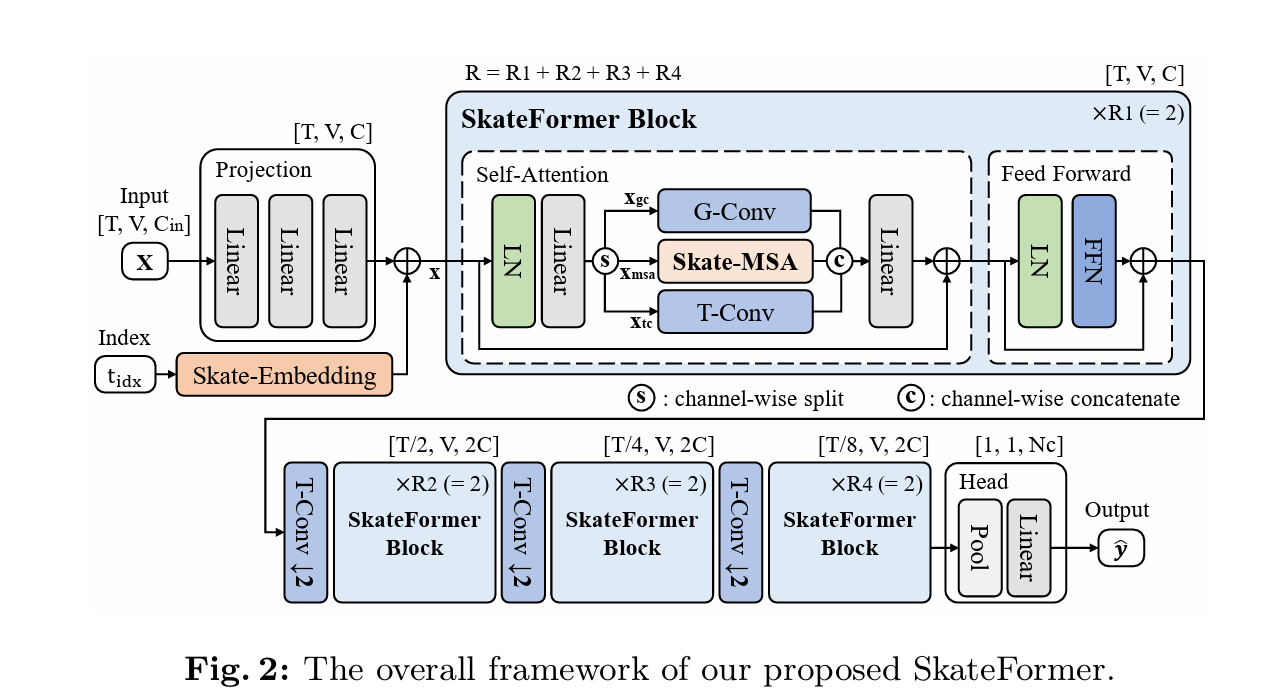 SkateFormer块的自注意力计算: \[
\begin{equation}
\begin{split}
&[\mathbf{x}_{\mathsf{gc}}, \mathbf{x}_{\mathsf{tc}},
\mathbf{x}_{\mathsf{msa}}] =
\mathsf{Split}(\mathsf{Linear}(\mathsf{LN}(\mathbf{x})))\\
&\mathbf{x}_{\mathsf{gc}} \leftarrow \mathsf{G{\text
-}Conv}(\mathbf{x}_{\mathsf{gc}})\\
&\mathbf{x}_{\mathsf{tc}} \leftarrow \mathsf{T{\text
-}Conv}(\mathbf{x}_{\mathsf{tc}})\\
&\mathbf{x}_{\mathsf{msa}} \leftarrow \mathsf{Skate{\text
-}MSA}(\mathbf{x}_{\mathsf{msa}})\\
&\mathbf{x} \leftarrow \mathbf{x} +
\mathsf{Linear}(\mathsf{Concat}(\mathbf{x}_{\mathsf{gc}},
\mathbf{x}_{\mathsf{tc}}, \mathbf{x}_{\mathsf{msa}})),
\end{split}
\end{equation}
\]
SkateFormer块的自注意力计算: \[
\begin{equation}
\begin{split}
&[\mathbf{x}_{\mathsf{gc}}, \mathbf{x}_{\mathsf{tc}},
\mathbf{x}_{\mathsf{msa}}] =
\mathsf{Split}(\mathsf{Linear}(\mathsf{LN}(\mathbf{x})))\\
&\mathbf{x}_{\mathsf{gc}} \leftarrow \mathsf{G{\text
-}Conv}(\mathbf{x}_{\mathsf{gc}})\\
&\mathbf{x}_{\mathsf{tc}} \leftarrow \mathsf{T{\text
-}Conv}(\mathbf{x}_{\mathsf{tc}})\\
&\mathbf{x}_{\mathsf{msa}} \leftarrow \mathsf{Skate{\text
-}MSA}(\mathbf{x}_{\mathsf{msa}})\\
&\mathbf{x} \leftarrow \mathbf{x} +
\mathsf{Linear}(\mathsf{Concat}(\mathbf{x}_{\mathsf{gc}},
\mathbf{x}_{\mathsf{tc}}, \mathbf{x}_{\mathsf{msa}})),
\end{split}
\end{equation}
\]
Skate-MSA
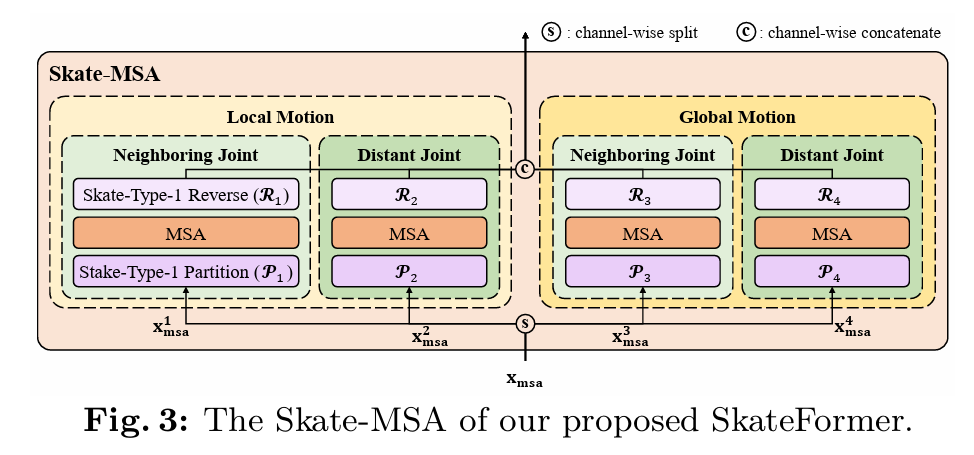 特征图 \(\mathbf{x}_{\mathsf{msa}}\)
首先按通道划分为四个相等大小的特征 \(\mathbf{x}_{\mathsf{msa}}^{1},
\mathbf{x}_{\mathsf{msa}}^{2}, \mathbf{x}_{\mathsf{msa}}^{3},
\mathbf{x}_{\mathsf{msa}}^{4}\),每个特征具有 \(C/8\)
个通道,自注意力操作被应用于区分对应于特定关系类型的关节之间的相关性,如下所示:
\[
\begin{equation}
\begin{split}
&\mathbf{x}_{\mathsf{msa}}^{i} \leftarrow
{\mathcal{R}}_{i}(\mathsf{MSA}({\mathcal{P}}_{i}(\mathbf{x}_{\mathsf{msa}}^{i})))
\\
&\mathbf{x}_{\mathsf{msa}} \leftarrow
\mathsf{Concat}(\mathbf{x}_{\mathsf{msa}}^{1},
\mathbf{x}_{\mathsf{msa}}^{2}, \mathbf{x}_{\mathsf{msa}}^{3},
\mathbf{x}_{\mathsf{msa}}^{4}),
\end{split}
\end{equation}
\]
特征图 \(\mathbf{x}_{\mathsf{msa}}\)
首先按通道划分为四个相等大小的特征 \(\mathbf{x}_{\mathsf{msa}}^{1},
\mathbf{x}_{\mathsf{msa}}^{2}, \mathbf{x}_{\mathsf{msa}}^{3},
\mathbf{x}_{\mathsf{msa}}^{4}\),每个特征具有 \(C/8\)
个通道,自注意力操作被应用于区分对应于特定关系类型的关节之间的相关性,如下所示:
\[
\begin{equation}
\begin{split}
&\mathbf{x}_{\mathsf{msa}}^{i} \leftarrow
{\mathcal{R}}_{i}(\mathsf{MSA}({\mathcal{P}}_{i}(\mathbf{x}_{\mathsf{msa}}^{i})))
\\
&\mathbf{x}_{\mathsf{msa}} \leftarrow
\mathsf{Concat}(\mathbf{x}_{\mathsf{msa}}^{1},
\mathbf{x}_{\mathsf{msa}}^{2}, \mathbf{x}_{\mathsf{msa}}^{3},
\mathbf{x}_{\mathsf{msa}}^{4}),
\end{split}
\end{equation}
\]
其中,\({\mathcal{P}}_{i}\) 和 \({\mathcal{R}}_{i}\) 分别表示第 \(i\) 个Skate-Type分区和反转操作。
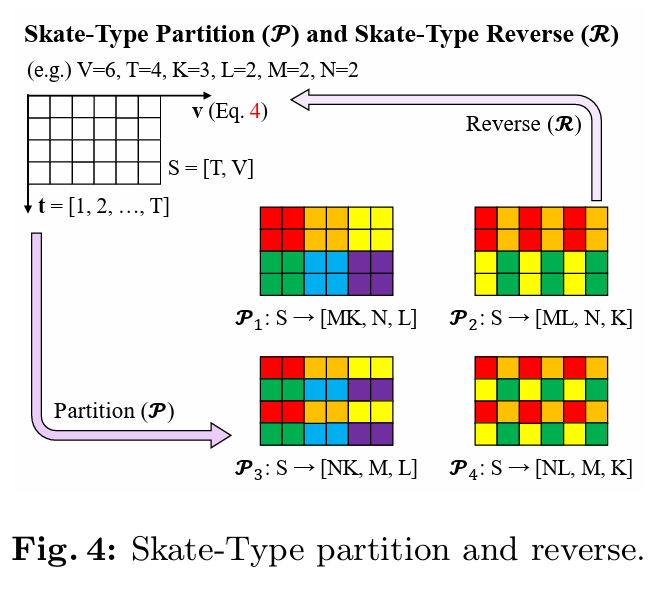 实际上就是把空间和时间按不同的规则分组: 1. \(K\)
为关节集合按照身体部分进行划分的子集数,如在NTU数据集上划分如下图,可以理解为\(K=6\),(实际上为12,因为人数为2,而且去掉了中心的关节点)
实际上就是把空间和时间按不同的规则分组: 1. \(K\)
为关节集合按照身体部分进行划分的子集数,如在NTU数据集上划分如下图,可以理解为\(K=6\),(实际上为12,因为人数为2,而且去掉了中心的关节点)
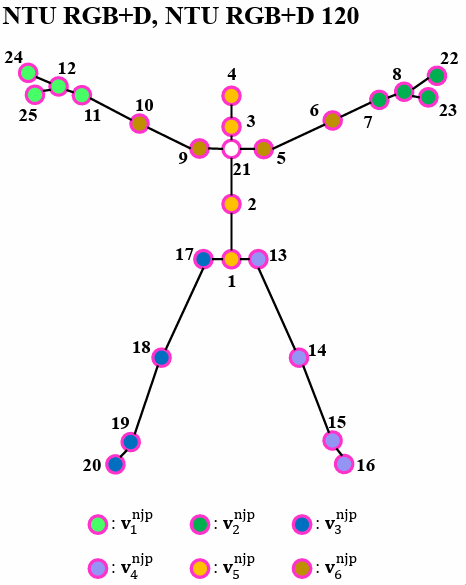
\(L\)为\(K\)个子集中的元素按照从身体中心区域向外扩展的方式排序的序号,类似于由内而外的分组。
时间上也按照类似的定义 \(\mathbf{t} = \left[1, 2, ..., T\right]\) 作为时间轴。我们进一步定义两个语义时间轴,\(\mathbf{t}_{m}^{\mathsf{local}}\) 用于局部运动理解,\(\mathbf{t}_{n}^{\mathsf{global}}\) 用于全局运动理解,如下所示:\[ \begin{equation} \begin{split} &\mathbf{t}_{m}^{\mathsf{local}} = \left[(m-1)N+1, (m-1)N+2, ..., mN\right]\\ &\mathbf{t}_{n}^{\mathsf{global}} = \left[n, n+N, ..., n+(M-1)N\right],\\ \end{split} \end{equation} \]\(\mathbf{t}_{m}^{\mathsf{local}}\) 是一段长度为\(N\)的连续时间段,用于表示时间段内的局部运动,而 \(\mathbf{t}_{n}^{\mathsf{global}}\) 是一个 \(N\) 步长的稀疏时间轴,用于捕捉时间 \(\mathbf{t}\) 上的全局运动。因此,有 \(\mathbf{t} = \{\mathbf{t}_{m}^{\mathsf{local}}\}_{m=1}^{M} = \{\mathbf{t}_{n}^{\mathsf{global}}\}_{n=1}^{N}\),且 \(|\mathbf{t}| = MN = T\)。根据骨骼-时间关系将关节和帧分成四种类型,用于 Skate-MSA 中的骨骼-时间分区,分别为 Skate-Type-1、-2、-3 和 -4:(i) Skate-Type-1 分区,表示为 \({\mathcal{P}}_{1}\),针对邻近关节和局部运动的自注意力分支,基于 \(\mathbf{v}_{k}^{\mathsf{njp}}\) 和 \(\mathbf{t}_{m}^{\mathsf{local}}\);(ii) Skate-Type-2 分区 \(({\mathcal{P}}_{2})\) 表示为针对远距离关节和局部运动的分支,基于 \(\mathbf{v}_{l}^{\mathsf{djp}}\) 和 \(\mathbf{t}_{m}^{\mathsf{local}}\);(iii) Skate-Type-3 分区 \(({\mathcal{P}}_{3})\) 表示为邻近关节和全局运动的分支,基于 \(\mathbf{v}_{k}^{\mathsf{njp}}\) 和 \(\mathbf{t}_{n}^{\mathsf{global}}\);(iv) 最后,Skate-Type-4 分区 \(({\mathcal{P}}_{4})\) 对应于针对远距离关节和全局运动的分支,基于 \(\mathbf{v}_{l}^{\mathsf{djp}}\) 和 \(\mathbf{t}_{n}^{\mathsf{global}}\)。Skate-Type 分区操作将 \(\mathbf{x}_{\mathsf{msa}}^{i}\) 的形状 \((S = (T, V, c))\) 转换为:\[ \begin{equation} \begin{split} {\mathcal{P}}_{1}: S &\rightarrow (MK, N, L, c) \quad {\mathcal{P}}_{2}: S \rightarrow (ML, N, K, c) \\ {\mathcal{P}}_{3}: S &\rightarrow (NK, M, L, c) \quad {\mathcal{P}}_{4}: S \rightarrow (NL, M, K, c), \end{split} \end{equation} \]其中 \(c = C/8\)。分区后的特征图 \(\mathbf{x}_{\mathsf{msa}}^{i, {\mathcal{P}}} = {\mathcal{P}}_{i}(\mathbf{x}_{\mathsf{msa}}^{i})\) 经过多头自注意力(\(\mathsf{MSA}\))处理,然后通过 Skate-Type 反向操作 \({\mathcal{R}}_{i}\)重新调整为其原始大小 \((T, V, c)\)。 ## Skeletal-Temporal Positional Embedding
Intra-instance augmentation: 每个帧序列内进行的数据增强。作者采用了两类数据增强:1)时间增强:通过固定步幅或随机采样整个输入来对输入帧进行时间采样;2)骨架增强:应用了各种变换,如演员顺序置换、随机剪切、随机旋转、随机缩放、随机坐标丢弃和随机关节丢失等。 作者新提出带\(p\)部分的修剪均匀随机帧采样。该采样剪切了总输入序列的前部和后部,并对帧进行均匀随机采样,预计骨架序列的前部和后部的遮罩效果,以及中间更密集的采样效果。
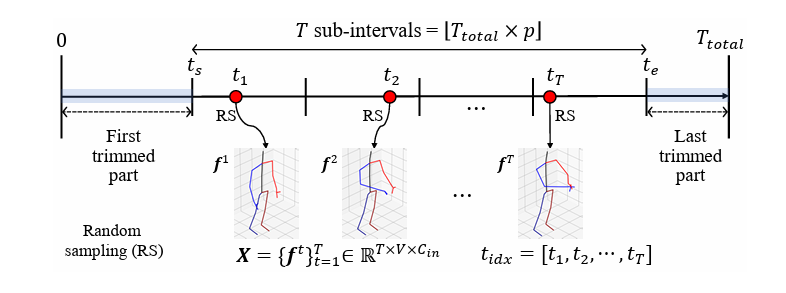
Inter-instance augmentation:通过在不同帧序列之间交换不同主体的骨骼长度来进行数据增强(而不是在每个帧序列内部)
Skate-Embedding: 提出了Skate-Embedding,它利用了固定(非可学习)的时间索引特征和可学习(非固定)的骨骼特征。时间索引特征适用于向第一个SkateFormer块传递来自各种长度序列的采样帧的时间位置信息。采样的时间索引被指定为\(t_{\mathsf{idx}} = [t_{1}, t_{2}, ..., t_{T}]\),如上图所示。然后将这些时间索引归一化到范围\([-1, 1]\),并且像在时间位置嵌入中一样,用于固定的时间索引特征。固定的时间索引特征表示为\(\mathsf{TE} \in \mathbb{R}^{T \times C}\),通过使用正弦位置嵌入构造\(t_{\mathsf{idx}}\)。另一方面,作为骨骼关节位置(不是关节的3D坐标而是它们的索引)的嵌入,可学习的骨骼特征表示为\(\mathsf{SE} \in \mathbb{R}^{V \times C}\),在Skate-Embedding中学习。最后,通过取\(\mathsf{SE}\)和\(\mathsf{TE}\)的外积得到骨骼-时间位置嵌入\(\mathsf{STE} \in \mathbb{R}^{T \times V \times C}\),即\(\mathsf{STE}[i, j, d] = \mathsf{SE}[j, d]\cdot \mathsf{TE}[i, d]\),其中\(i\)表示第\(i\)个时间,\(j\)表示第\(j\)个关节,\(d\)表示第\(d\)个通道。(这块还是得看具体代码)
实验
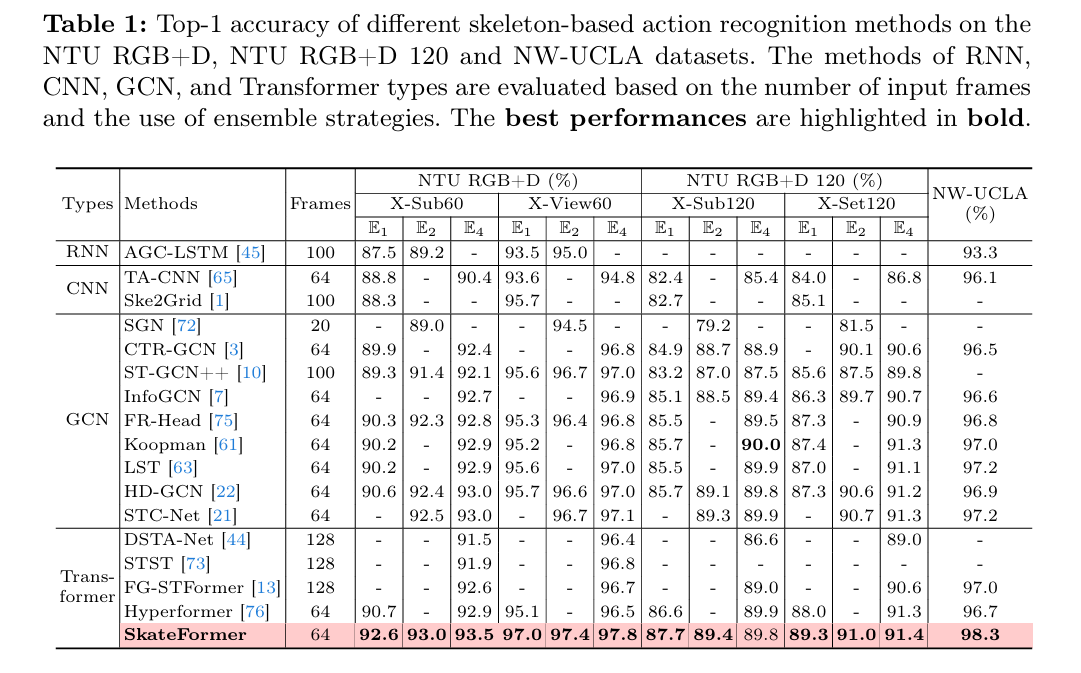
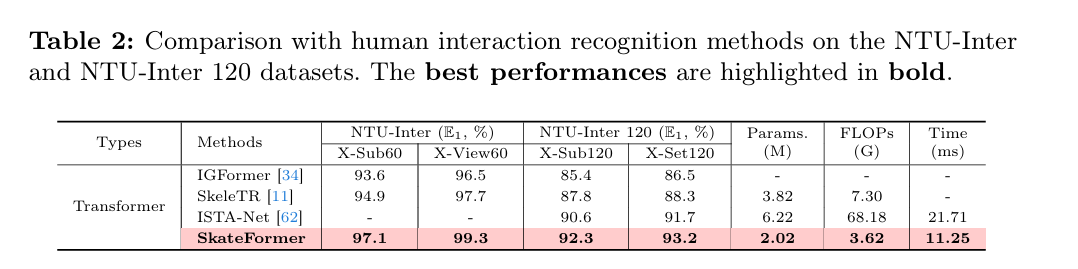
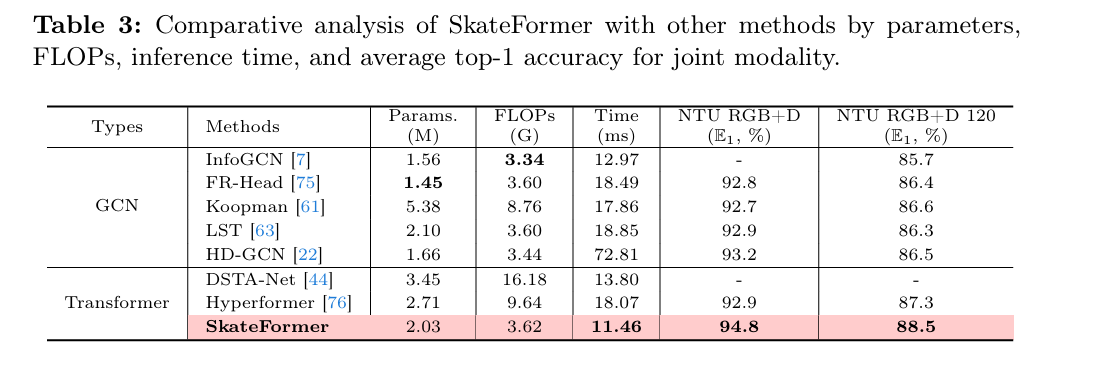
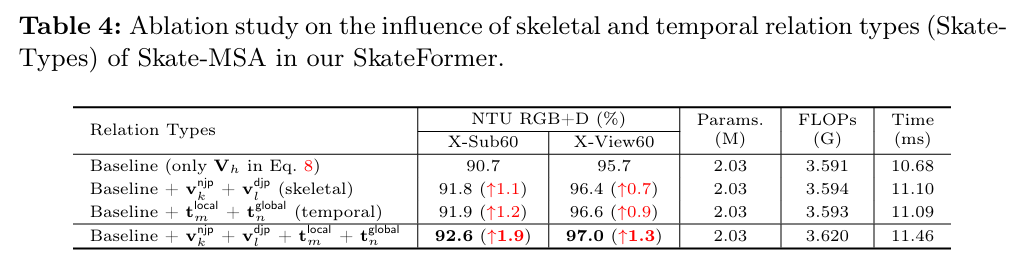 表4展示了不同Skate-Type对Acc的影响,仅考虑骨骼关系类型相对于基线提高了动作分类性能,仅考虑时间关系类型也是如此。而利用Skate-Type(骨骼-时间关系类型)的完整模型实现了最高的准确率,表明骨骼和时间分离对于区分复杂动作至关重要。
表4展示了不同Skate-Type对Acc的影响,仅考虑骨骼关系类型相对于基线提高了动作分类性能,仅考虑时间关系类型也是如此。而利用Skate-Type(骨骼-时间关系类型)的完整模型实现了最高的准确率,表明骨骼和时间分离对于区分复杂动作至关重要。
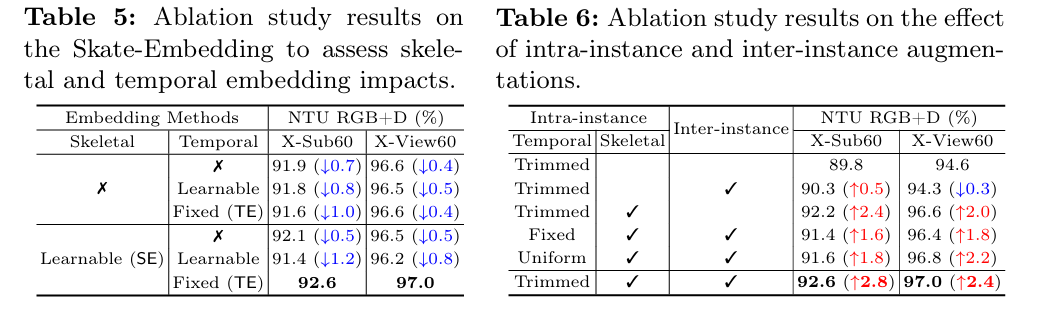 表5对STE进行消融,可以看出可学习的骨骼嵌入 (\(\mathsf{SE}\)) 搭配固定的时间嵌入 (\(\mathsf{TE}\))
实现了更优秀的性能;表6对比了三种三种帧采样策略,包括 (i) 固定步幅
(Fixed)、(ii) 均匀随机 (Uniform) 和 (iii) 新提出的修剪均匀随机 (Trimmed)
采样方法;表6同时也展示了内部实例(传统)和外部实例(额外)数据增强的有效性。
表5对STE进行消融,可以看出可学习的骨骼嵌入 (\(\mathsf{SE}\)) 搭配固定的时间嵌入 (\(\mathsf{TE}\))
实现了更优秀的性能;表6对比了三种三种帧采样策略,包括 (i) 固定步幅
(Fixed)、(ii) 均匀随机 (Uniform) 和 (iii) 新提出的修剪均匀随机 (Trimmed)
采样方法;表6同时也展示了内部实例(传统)和外部实例(额外)数据增强的有效性。