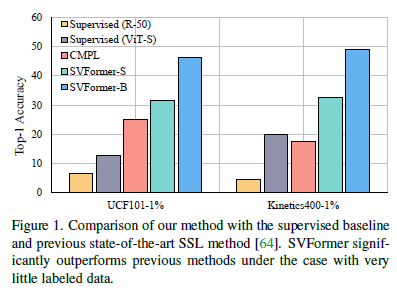
SVFormer: Semi-supervised Video Transformer for Action Recognition
摘要
半监督动作识别是一项具有挑战性但又至关重要的任务,因为视频注释的成本很高。现有方法主要使用卷积神经网络,然而当前的革命性视觉Transformer模型尚未得到充分探索。在本文中,我们研究了在半监督学习(SSL)设置下使用Transformer模型进行动作识别的方法。为此,我们引入了SVFormer,它采用了稳定的伪标签框架(即EMATeacher)来处理无标签视频样本。虽然广泛的数据增强方法已被证明对于半监督图像分类是有效的,但对于视频识别而言,它们通常产生有限的结果。因此,我们引入了一种针对视频数据的新型增强策略,称为Tube Token-Mix,其中视频剪辑通过掩码和一致的遮蔽标记在时间轴上混合。此外,我们提出了一种时域扭曲增强方法,用于覆盖视频中复杂的时域变化,它将选定的帧在剪辑中拉伸到不同的时间长度。对三个数据集Kinetics-400、UCF-101和HMDB-51进行了大量实验证实了SVFormer的优势。特别是,在Kinetics-400的1%标注率下,SVFormer在较少的训练周期内比现有技术提升了31.5%。我们的方法有望作为一个强有力的基准,并鼓励未来在使用Transformer网络进行半监督动作识别方面的研究。
引言
论文背景:目前,视频在互联网上逐渐取代了图像和文字,并以指数级的速度增长。有监督的视频理解已经取得了巨大的成功,但这些工作依赖于大规模手工标注,因此利用现成的无标签视频来更好地理解视频是非常重要的。
过去方案:半监督方法通常基于伪标签的模式,通常是用已标记数据来预训练网络,然后利用预训练的模型为未标记的数据生成伪标签,最后使用伪标签进一步改进预训练模型。学界通常采用额外模态(比如光流)或者辅助网络的方式提高伪标签的质量,但这类方法会带来额外的训练或推理成本。
论文的Motivation:鉴于TransFormer架构在视频领域的巨大成功,而原有的SSL方法(如Mixup和CutMix)并不适用于TransFormer架构,本文旨在提出一种基于TransFormer的半监督动作识别方法,并提出一种适用于TransFormer架构的增强方法,能够更好地对token之间的时间相关性进行建模。另外,本文还提出一种时间扭曲增强方法可以覆盖视频中复杂的时间变化。
论文的Contribution:
- 率先探索了半监督视频识别的变压器模型。
- 提出了一种token级增强方法Tube Token-Mix,它比像素级混合策略更适合视频Transformer。
- 在三个基准数据集上进行了广泛的实验,达到了SOTA。
方法
SSL设置
假设我们有N个训练视频样本,包括N_L个带有标签的视频样本\((x_l,y_l) \in \mathcal{D}_L\)和\(N_U\)个无标签的视频样本\(x_u \in \mathcal{D}_U\),其中\(x_l\)是带有类别标签\(y_l\)的标记视频样本,\(x_u\)是无标签的视频样本。通常情况下,\(N_U \gg N_L\)。半监督学习的目标是利用\(\mathcal{D}_L\)和\(\mathcal{D}_U\)来训练模型。
Pipeline
SVFormer采用了流行的半监督学习框架FixMatch,该框架利用两个不同增强视图之间的一致性损失。训练范式分为两个部分。
对于标记集合\(\{(x_l, y_l)\}_{l=1}^{N_L}\),模型优化有监督损失\({\cal{L}}_{s}\): $$ \[\begin{equation} {\cal{L}}_{s}=\frac{1}{N_L}\sum_{}^{N_L}{\cal{H}}({\cal{F}} ({x_l}),y_l), \end{equation}\] $$ 其中\({\cal{F}}(\cdot)\)表示模型产生的预测,\({\cal{H}}\)是标准的交叉熵损失函数。
对于无标签样本\(x_u\),我们首先使用弱增强(例如,随机水平翻转、随机缩放和随机裁剪)和强增强(例如,AutoAugment或Dropout)分别生成两个视图,\(x_w={\cal{A}}_{weak}(x_u)\),\(x_s={\cal{A}}_{strong}(x_u)\)。然后,利用模型生成的弱视图的伪标签\({\hat{y}_w}=\arg\max({\cal{F}}(x_w))\)来监督强视图,使用以下无监督损失: \[ \begin{equation} {\cal{L}}_{un}=\frac{1}{N_U}\sum^{N_U}{\mathbb{I}} (\max({\cal{F}}(x_w)) > \delta){\cal{H}}({\cal{F}}({x_s}),\hat{y}_w), \end{equation} \] 其中\(\delta\)是预定义的阈值,\({\mathbb{I}}\)是指示函数,当最大类别概率超过\(\delta\)时,它的值为1,否则为0。置信度指标用于过滤嘈杂的伪标签。
在FixMatch中,两个增强的输入共享同一个模型,这容易导致模型容易崩溃 。因此,论文采用了指数移动平均(EMA)-Teacher,这是FixMatch的改进版本。 伪标签是由EMA-Teacher模型生成的,该模型的参数通过对学生参数进行指数移动平均来更新,具体表示为: \[ \begin{equation} {\theta}_t \gets m {\theta}_t +(1- m) {\theta}_s, \end{equation} \] 其中\(m\)是一个动量系数,\(\theta_{t}\)和\(\theta_{s}\)分别是教师模型和学生模型的参数。
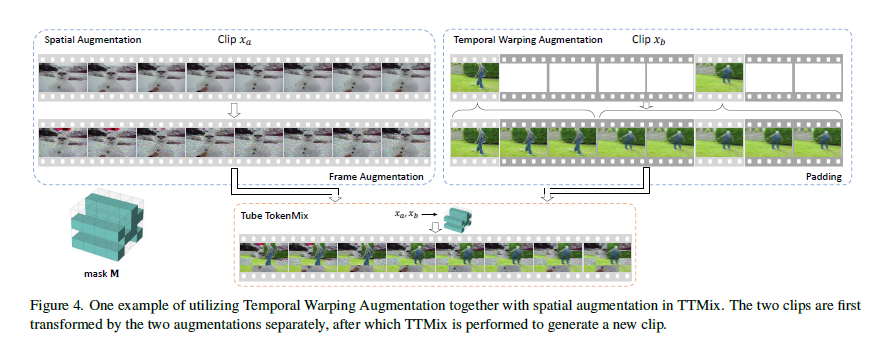
Tube TokenMix
在半监督框架中,一个核心问题是如何使用高质量的伪标签丰富数据集。 Mixup 是一种广泛采用的数据增强策略,它通过以下方式在样本和标签之间执行凸组合: \[ \begin{equation} \hat{x} = \lambda \cdot x_1 + (1-\lambda) \cdot x_2, \end{equation} \] \[ \begin{equation} \hat{y} = \lambda \cdot y_1 + (1-\lambda) \cdot y_2, \end{equation} \] 其中比例 \(\lambda\) 是一个符合贝塔分布的标量。Mixup及其变种(例如CutMix)在低数据情况下的许多任务中取得了成功,例如长尾分类、域自适应、少样本学习等等。对于半监督学习,Mixup 通过在图像分类中混合无标签样本的伪标签也表现良好。
视频Mixing
对于基于TransFormer的方法,原本像素级的mixing增强方法(Mixup 或CutMix)并不适用于token级的模型。因此论文提出三种用于视频数据的mixing增强方法:Rand TokenMix、Frame TokenMix和Tube TokenMix。
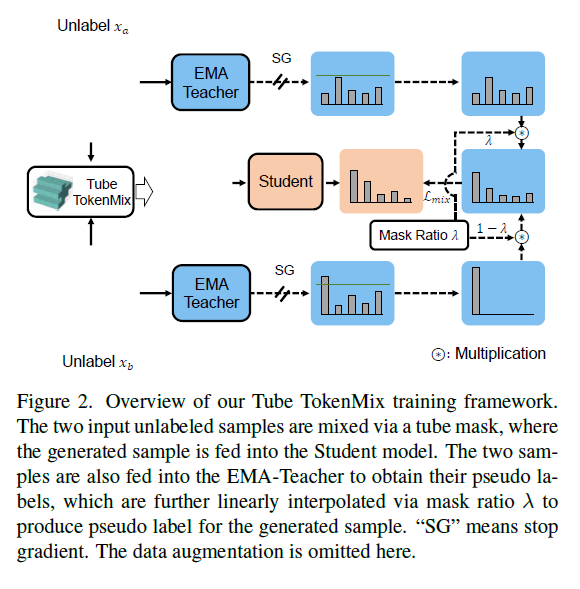
给定未标记的视频片段\(x_a, x_b\in \mathbb{R}^{H\times W\times T}\),使用一个基于标记的掩码\(\textbf{M}\in\{0,1\}^{H\times W\times T}\)来执行样本混合。这里\(H\)和\(W\)分别表示经过分块标记化后的帧的高度和宽度,\(T\)表示片段长度。为了生成一个新的样本\(x_{mix}\),在进行强数据增强\({\cal{A}}_{strong}\)后,按照以下方式混合\(x_a\)和\(x_b\): \[ \begin{equation} x_{mix} = {\cal{A}}_{strong}(x_a) \odot \textbf{M} + {\cal{A}}_{strong}(x_b) \odot (\textbf{1}-\textbf{M}), \end{equation} \] 其中\(\odot\)表示逐元素相乘,\(\textbf{1}\)是一个全为1的二值掩码。
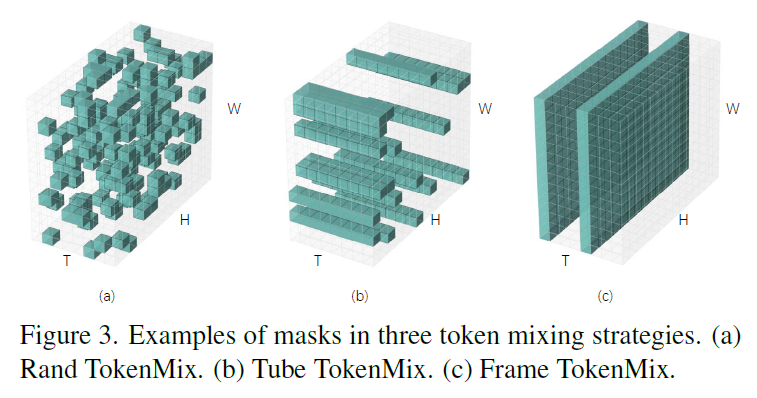
在三种增强方法中,掩码\(\textbf{M}\)的处理方式不同,如图所示。 对于Rand TokenMix,被掩盖的标记是从整个视频剪辑中(\(H\times W\times T\)个标记)随机选择的。 对于Frame TokenMix,从\(T\)个帧中随机选择一些帧,并将这些帧中的所有标记进行掩盖。 对于Tube TokenMix,采用了管道式的掩盖策略,即不同帧共享相同的空间掩码矩阵。在这种情况下,掩码\(\textbf{M}\)在时间轴上具有一致的掩盖标记。
利用上述的增强方法可以掩码混合两个片段并合成一个新的混合数据样本,然后,混合样本\(x_{mix}\)被馈送到学生模型\({\cal{F}}_{s}\),得到模型预测\(y_{mix} = {\cal{F}}_{s}(x_{mix})\)。 此外,通过将弱增强样本\({\cal{A}}_{weak}(x_a)\)和\({\cal{A}}_{weak}(x_b)\)输入到教师模型\({\cal{F}}_{t}\)中,产生\(x_a\)和\(x_b\)的伪标签\(\hat{y}_a,\hat{y}_b\): \[ \begin{equation} \hat{y}_a = \arg\max({\cal{F}}_{t}({\cal{A}}_{weak}(x_a))), \end{equation} \] \[ \begin{equation} \hat{y}_b = \arg\max({\cal{F}}_{t}({\cal{A}}_{weak}(x_b))). \end{equation} \] 注意,如果\(\max({\cal{F}}_{t}({\cal{A}}_{weak}(x)))<\delta\),则伪标签\(\hat{y}\)保持软标签\({\cal{F}}_{t}({\cal{A}}_{weak}(x))\)不变。 对于\(x_{mix}\),伪标签\(\hat{y}_{mix}\)通过使用掩码比例\(\lambda\)混合\(\hat{y}_a\)和\(\hat{y}_b\)生成: \[ \begin{equation} \hat{y}_{mix} = \lambda \cdot \hat{y}_a + (1-\lambda) \cdot \hat{y}_b. \end{equation} \] 最后,学生模型通过以下一致性损失进行优化: $$ \[\begin{equation} {\cal{L}}_{mix}= \frac{1}{N_{m}} \sum^{N_{m}}(\hat{y}_{mix} - y_{mix})^2, \end{equation}\] $$ 其中\(N_{m}\)是混合样本的数量。 TTMix的一致性损失算法显示在算法:Consistency loss for Tube TokenMix中。

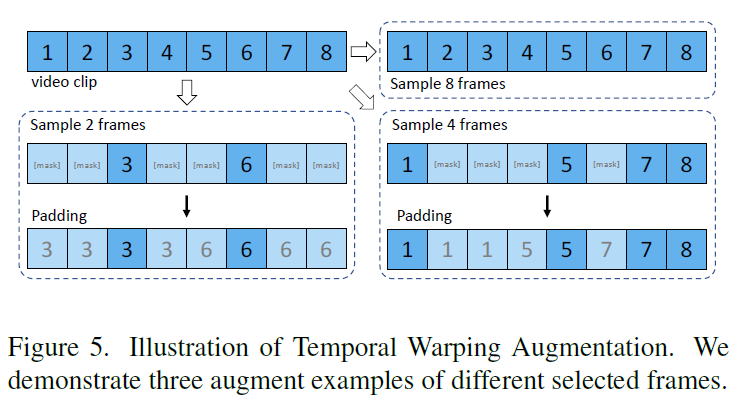
时间扭曲增强 Temporal Warping Augmentation
作者提出扭曲每个帧的时间持续性,从而将更高的随机性引入数据中。时间扭曲增强(TWAug)可以将一个帧的时间长度拉伸到各种不同的值。 给定一个包含\(T\)帧(例如,8帧)的提取视频片段,随机决定保留所有帧,或者选择一小部分帧(例如,2或4帧),并遮盖其他帧。 然后,被遮盖的帧会用随机的相邻可见(未遮盖)帧进行填充。 请注意,在进行时间填充后,帧的顺序仍然保持不变。 下图分别显示了选择2、4和8帧的三个示例。 提出的TWAug可以帮助模型在训练过程中学习灵活的时间动态。
训练模式
SVFormer的训练由三个部分组成:由式(1)给出的有监督损失、由式(2)给出的无监督伪标签一致性损失以及由式(10)给出的TTMix一致性损失。最终的损失函数如下所示: \[ \begin{equation} {\cal{L}}_{all}= {\cal{L}}_{s} + {\gamma}_1 {\cal{L}}_{un} + {\gamma}_2 {\cal{L}}_{mix}, \end{equation} \] 其中\({\gamma}_1\)和\({\gamma}_2\)是平衡损失项的超参数。