Efficient Video Understanding
Prompting Visual-Language Models for Efficient Video Understanding
ECCV2022
基于图像的视觉语言模型
Pre-training
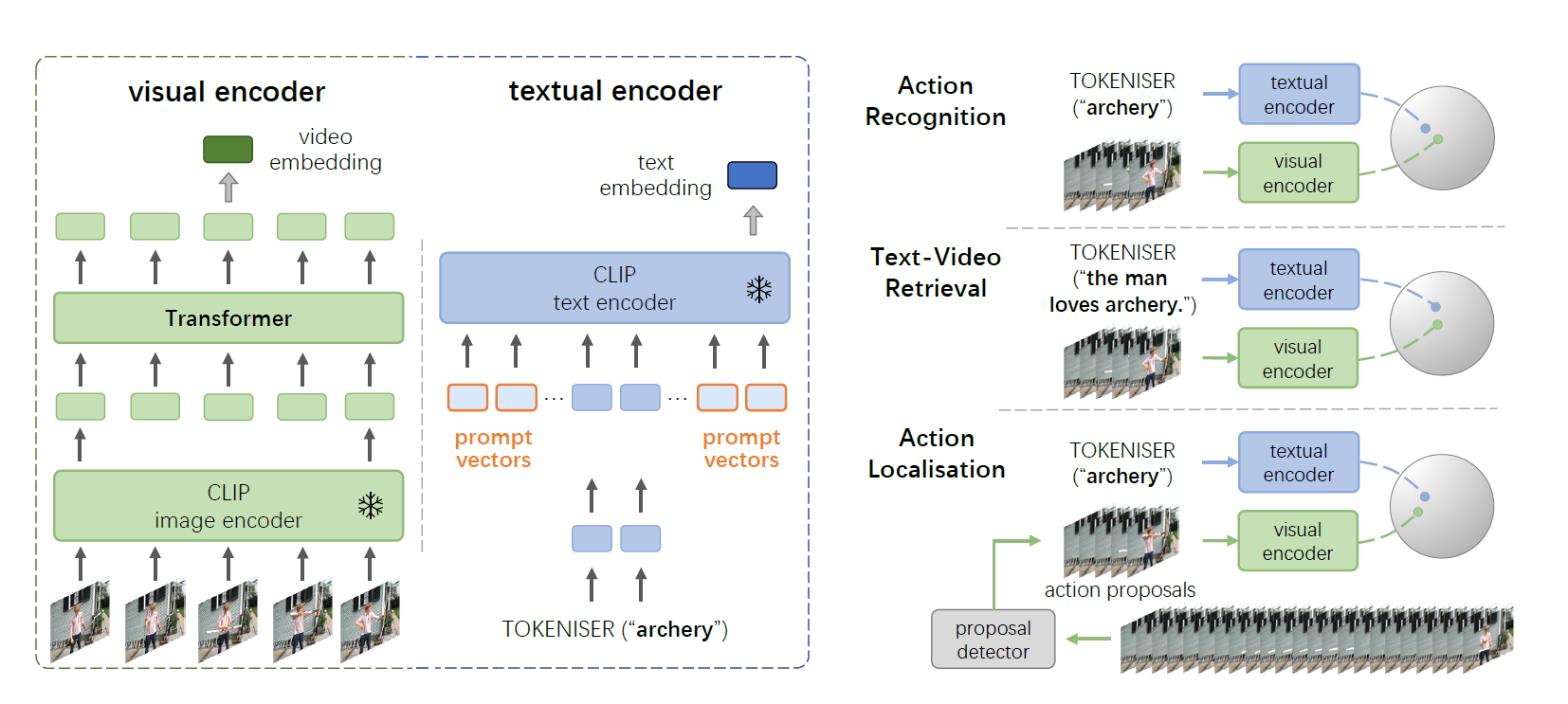
给定一个batch的N对(图像,文本),使用两个单独的编码器计算图像和文本的feature embeddings,并计算所有N个可能的(图像,文本)对之间的密集余弦相似度矩阵。训练目标是联合优化图像和文本编码器,通过最大化N对正确的(图像,文本)关联之间的相似性,同时通过密集矩阵上的对称交叉熵最小化N ×(N−1)错误对的相似性,即噪声对比学习。这两个编码器都包含一个tokeniser,用于将图像补丁或语言单词转换为向量,也就是会有visual tokens和textual tokens。
Inference
训练完成之后,I-VL模型便可以部署在开放词汇表上的图像分类任务,通过使用从文本编码器\(\Phi_{\text{text}}\)生成相应的视觉分类器完成分类任务。举例来说,如果为了分辨一张图片是猫还是狗,那分类器(\(c_{cat}\)和\(c_{dog}\))可以生成为: \[ \begin{aligned}c_{\mathrm{cat}}&=\Phi_{\mathrm{text}}(\mathrm{TOKENISER}(\text{“this is a photo of}[\underline{cat}]\text{''}))\\ c_{\mathrm{dog}}&=\Phi_{\operatorname{text}}(\mathrm{TOKENISER}(\text{“this is a photo of}[\underline{dog}]\text{''}))\end{aligned} \] 而“this is a photo of [·]”是手工制作的提示模板,可以被有效地用于图像分类。
Discussion
尽管在零样本图像分类方面取得了巨大的成功,I-VL模型也显示出对手工制作的提示模板很敏感,显然对其对新的下游任务的有效适应造成了限制,在这些任务中,专家知识可能很难浓缩或不可用。因此,考虑将这种提示设计过程自动化,探索有效的方法,以使预训练的基于图像的视觉-语言模型适应新的下游任务,而训练数量最少。
视频理解Prompting CLIP
作者认为I-VL模型上的prompt learning会在视频领域大放异彩主要有两个原因:(实际上感觉和用图像理解的模型去预训练视频理解模型类似) 1. 视频任务需要大量的资源。具体来说,视频-文本对更难收集且训练计算成本更高,因此通过训练大规模的基于图像的视觉文本模型(I-VL),并且prompt进行高效的视频理解更好(类似于图像迁移到视频?)。 2. 视频由帧序列组成,在强大的基于图像的模型上建立时间依赖性是一个自然且经济的选择。
问题设想
数据集表示为\(\mathcal{D} = \{ \mathcal{D}_{\text{train}}, \mathcal{D}_{\text{val}} \}\),e.g.\(\mathcal{D}_{\text{train}} = \{(\mathcal{V}_1, y_1), \dots, (\mathcal{V}_n, y_n) \}\),其中视频为\(\mathcal{V}_i \in \mathbb{R}^{T \times H \times W \times 3}\),而标签\(y_i\)根据下游任务的不同而有不同的情况:识别任务为\(c_{train}\)中的动作标签、定位任务为密集的动作类别标签的T时间戳、检索任务为细粒度文本描述。
在closed-set的情况下,训练和验证的动作类别是相同的;零样本情况下,训练和验证的动作类别是不相关的。
基于提示学习的模型自适应
主要目的是引导预训练只需最少的训练即可执行各种视频任务。具体而言,通过将连续随机向量序列(“提示向量”)与文本标记预先/追加,实现高效的模型适应。在训练时,CLIP的图像和文本编码器都保持冻结,梯度将通过文本编码器,只更新提示向量。最终,这些可学习的向量将构建文本编码器可以理解的“虚拟”提示模板,并生成所需的分类器或查询嵌入,详细内容如下
- 动作识别:为了生成动作分类器,我们通过将标记化的类别名称输入预训练的文本编码器\(\mathrm{\Phi}_{\text{text}}\)来构造“虚拟”提示模板,如下式,其中\(a_i \in \mathbb{R} ^{D}\)表示第i个提示向量,由几个可学习参数组成,\(D\)是向量维度。提示向量\(\{a_i\}\)会与所有的动作类别共享,也就是只是对于任务是专有的。 \[ \begin{align*} &c_{\text{archery}} = \mathrm{\Phi}_{\text{text}}(a_{1}, \dots, \mathrm{TOKENISER}(\text{''}\text{\underline{archery}''}), \dots, a_{k}) \\ &c_{\text{bowling}} = \mathrm{\Phi}_{\text{text}}(a_{1}, \dots, \mathrm{TOKENISER}(\text{''}\text{\underline{bowling}''}), \dots, a_{k}) \end{align*} \]
- 动作定位:采用two-stage范式,首先检测潜在的类别未知动作建议(详见第4.1节),然后对这些检测到的建议执行动作分类。
- 视频文字提取:类似地将整个句子标记化,并将标记化的结果与可学习的提示向量馈送到文本编码器,以生成每个句子的查询嵌入。
- 总结:一般来说,模型适应的学习提示有以下好处: 1)所有任务都可以使用同一个共享的backbone,并且能达到有竞争力的性能;2)适应新任务只需要优化少数提示向量,便于实现few-shot问题;3)能够更好地利用丰富的训练数据,并进一步泛化到封闭集类别之外。
时序建模
作者通过使用一个简单而轻量级的时序建模模块来弥补图像到视频之间的差距。具体来说,通过在冻结图像编码器的帧级特征上附加一个Transformer编码器将CLIP的图像encoder升级为视频encoder: \[ \begin{align*} v_i = \mathrm{\Phi}_{\text{video}}(\mathcal{V}_i) = \mathrm{\Phi}_(\{ \mathrm{\Phi}_{\text{image}}(I_{i1}), \dots, \mathrm{\Phi}_{\text{image}}(I_{iT})\}) \end{align*} \] 为了表示时间顺序,图像特征上添加了可学习的时间位置编码。\(v_i \in \mathbb{R} ^{T \times D}\)是\(T\)帧的密集特征嵌入。
训练loss
给定一批(视频,文本)训练对,视觉流最终得到密集的帧级特征嵌入~(\(v_i\));而对于文本流,根据考虑的下游任务,它最终会得到一组操作分类器(\(c_i \in \mathcal{C}_{\text{action}}\))或文本查询嵌入(\(c_i \in \mathcal{C}_{\text{query}}\))。对于动作识别和文本-视频检索,通过取密集特征的均值池来进一步计算视频片段级特征: \[ \begin{align} \overline{v}_i = \mathrm{\Phi}_{POOL}(v_i) \in \mathbb{R}^{1 \times D} \end{align} \] 对于动作定位,对每个检测到的动作建议中的密集特征进行平均池化,以获得提案级特征。为了简单起见,还将这个提议级别的特性表示为\(\overline{v}_i\)。 训练过程中,共同优化文本提示向量和时间Transformer,使得视频片段(提案)特征及其配对分类器或文本查询嵌入在其他特征中发出最高的相似性分数。这是通过简单的NCE损失实现的 \[ \begin{align} \mathcal{L} = &- \sum_i \big( \log \frac{\exp(\overline{v}_i \cdot c_{i} / \tau)}{\sum\limits_{j} \exp(\overline{v}_i \cdot c_j / \tau)} \big) \end{align} \]
Dual-path Adaptation from Image to Video Transformers
CVPR 2023
paper: https://arxiv.org/abs/2303.09857
code: https://github.com/park-jungin/dualpath
Baseline
Parameter-efficient transfer learning (PETL),参数高效迁移学习,在自然语言处理(NLP)中首次被使用,用于解决全/部分微调的内存和参数效率低下的问题。主要目标是通过仅使用少量可训练参数进行微调,在下游任务上获得相当或超过的性能。

- Visual prompt tuning (VPT) 在Transformer块的Input Tokens前添加\(K\)个可训练的prompt
token,同时冻结预训练的参数。Input Tokens为

- AdaptFormer学习一个可训练的bottleneck模块。这个模块会与Transformer块中的MLP层平行,即输入为中间特征\(z\),AdaptFormer block的输出可表示为

- Pro-tuning使用连续的2D卷积层从每个Transformer块的输出中预测特定于任务的视觉提示v。每个块的输出会被reshaped为
\(P \times P \times C\)以应用于2D卷积
。

- ST-adapter采用的adapter结构为在向下投影层和激活函数之间插入深度方向的3D卷积层。相较于AdaptFormer,ST-adapter会接受所有帧的token使得模型可以捕捉到视频中的时间特征。输出可表示为:


Spatial adaptation
即使在视频中,已经在大量的数据集上训练过的图像模型也可能对空间contexts进行编码,具有突出的空间建模能力。为了更适合视频理解,作者采用了两个平行于transformer块的MHA和MLP的adapter。平行adapter可以允许模型在保持用于识别对象的原始contexts的同时,能在视频的空间信息中学得可以用于动作识别的contexts。
空间token的集\(\mathbf{X}^{\text{SP}}_t\)包括可学习的位置编码\(\mathbf{p}^{SP}\)和空间class token \(\mathbf{x}_{t}^{\mathrm{SP}}\{[\mathrm{CLS}]\}\)。第\(l\)个transformer块的Spatial adaptation可由下列公式表示:

接着对来自最后一个transformer块的空间分类token进行平均以获得全局空间表示\(y^{sp}\)
Temporal adaptation
虽然Spatial adaptation能够使得图像模型适应视频数据中的空间contexts,但图像模型仍然无法对时间信息进行建模。使视频transformer能够建模时间context的关键是能够学习到视频中跨帧的局部patch之间的关系。因此,作者提出了一种新的类网格帧集转换技术,将多个帧聚合成一个统一的类网格帧集,能模拟空间和时间建模且大大减少计算量。在每个transformer块中,分别为MHA和MLP采用了两个额外的串行adapter。
在视频中采样\(T\)帧后,使用\(w\)和\(h\)的因子进行缩放,缩放后的帧大小为\([W/w \times H/h \times 3]\)。接着根据时间顺序堆叠\(w\times h\)个缩放帧,并重构堆叠帧,以与原始帧大小相同的网格形式构造一组帧,从而得到的类网格帧集的总数为\(T_G = T/wh\)。按同样的方式获得第\(g\)个帧集的时间token\(\mathbf{X}_g^{\text{TP}}\),并与可学习的时间分类token\(\mathbf{x}_{g}^{\mathrm{SP}}\{[\mathrm{CLS}]\}\)相结合。与Spatial adaptation不同,使用了固定3D位置编码\(\mathbf{p}^{TP}\),考虑到patch的绝对时间顺序和空间位置。作者依次将适配器附加到每个变压器块中的MHA和MLP层的顶部,第\(l\)个transformer块的temporal adaptation可由下列公式表示:

接着对来自最后一个transformer块的时间分类token进行平均以获得全局空间表示\(y^{sp}\)。对于最后的预测,将全局空间和时间表示连接起来,并将它们输入两个FC层之间具有GeLU激活的分类器。
AIM: Adapting Image Models for Efficient Video Action Recognition
ICLR 2023
paper: https://arxiv.org/abs/2302.03024
code: https://github.com/taoyang1122/adapt-image-models


空间 Adaptation
Adapter是在NLP上被广泛使用的一种高效微调技术。从图中(b)可以看出,Adapter是一个bottleneck架构,由两个全连接(FC)层和中间的激活层组成。为了使预训练的空间特征适应目标视频数据,空间Adaptation通过在自注意层后添加Adapter实现。在训练过程中,只更新Adapter的参数而冻结其他部分。
时间 Adaptation
作者提出了一个新的方法:复用图像模型中预先训练好的自注意层进行时间建模。 具体地说,他们将原始的自注意层表示为S-MSA用于空间建模,将复用的自注意层表示为T-MSA用于时间建模。可以在图中(c)看到,他们将T-MSA放在S-MSA前面,然后通过reshape的方法调整输入的embedding,使得同样的MSA可以用于不同的维度。与空间Adaptation一样,在MSA后加上了一个时间Adapter,但不同的是这个Adapter没有skip connection,原因是希望将适应模型初始化为接近原始模型。
联合 Adaptation
联合Adaptation就是在最后的MLP处加上了一个与其并行的Adapter,而这个Adapter的结构与时间Adaptation的一样,最后adapted block可被写为 \[ \begin{aligned} z^T_{l} &= z_{l-1} + \operatorname{Adapter}(\operatorname{T-MSA}(\operatorname{LN}(z_{l-1})))\\ z^S_{l} &= z^T_{l} + \operatorname{Adapter}(\operatorname{S-MSA}(\operatorname{LN}(z^T_{l})))\\ z_{l} &= z^S_{l} + \operatorname{MLP}(\operatorname{LN}(z^S_{l})) + s \cdot \operatorname{Adapter}(\operatorname{LN}(z^S_{l})) \end{aligned} \]