视频行为识别博客笔记
博客原文地址:Deep Learning for Videos: A 2018 Guide to Action Recognition (qure.ai)
动作识别以及难点
1.巨量的计算资源
一个简单的用于分类101类的卷积二维网络只有5M个参数,而同样的结构膨胀到3D结构时,会产生33M个参数。
2.需考虑上下时刻场景
动作识别需包含跨帧获取时空信息
3.设计分类网络结构
需设计能够捕获时空信息的架构
4.没有标准的benchmark
方法概述
传统CV方法
基本可汇总为以下三步:
1.针对视频明显特征区域做提取,提取为密集向量或稀疏的兴趣点集合。(这一步之前一直是人工提取,后来提出的iDT算法改善了该流程)
2.提取的特征转化为固定尺寸的向量,来描述该视频的内容。这一步最流行的做法是Bag of visual words
3.定义分类器,根据提取的视频特征向量,选定分类器,做分类训练和预测
深度学习方法
3D卷积于2013年被用于动作识别,且无需其他的输入作为帮助。而2014年有两篇突破性的研究论文被发表。
单流网络
https://static.googleusercontent.com/media/research.google.com/en//pubs/archive/42455.pdf
这篇论文使用2D预训练卷积以探索多种方法来融合连续帧的时间信息
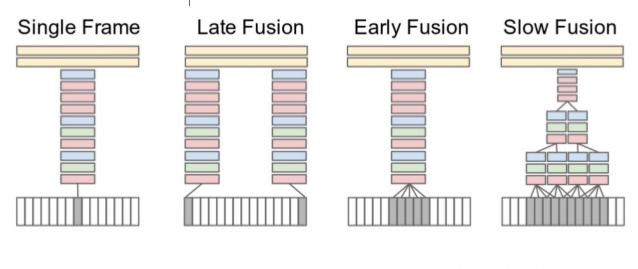
如上图,视频的所有连续帧都作为不同设置的输入。 Single frame 使用单一的网络架构在最后阶段融合所有帧的信息;Late fusion融合使用两个共享参数的网络,间隔15帧,并在最后结合预测。Early fusion在第一层通过卷积将超过10帧进行融合。 Slow fusion涉及多个阶段的融合,兼顾早期和晚期融合之间的平衡。
不过与基于人工标定特征的方法相比,效果不好,作者推断有以下问题:一是学习到的时空特征没有捕捉到运动特征;二是由于数据集的多样性较低,学习如此详细的特征非常困难
双流网络

https://arxiv.org/pdf/1406.2199.pdf
这篇论文在上文单流网络的基础上,设计一个获取动作特征的光流模型。这样就形成了双流模型,一个负责获取空间信息,一个负责获取时间信息。
尽管该方法取得了不错的效果,但还是有以下几个缺点: 一 视频的预测还是依据从视频中抽取的部分样本。对于长视频来说,在特征学习中还是会损失时序信息。 二 在训练时,从视频中抽取片段样本时由于是均匀抽取,这样会有错误标签的现象(即指定动作并不存在该样本片段中)。 三 在光流使用前,需要对视频预先做光流的抽取操作。
论文总结
以下论文在某种程度上是两篇论文(单流和两流)的演变。而围绕这些论文反复出现的方法可以总结如下,所有的论文都是基于这些基本观点的即兴创作。
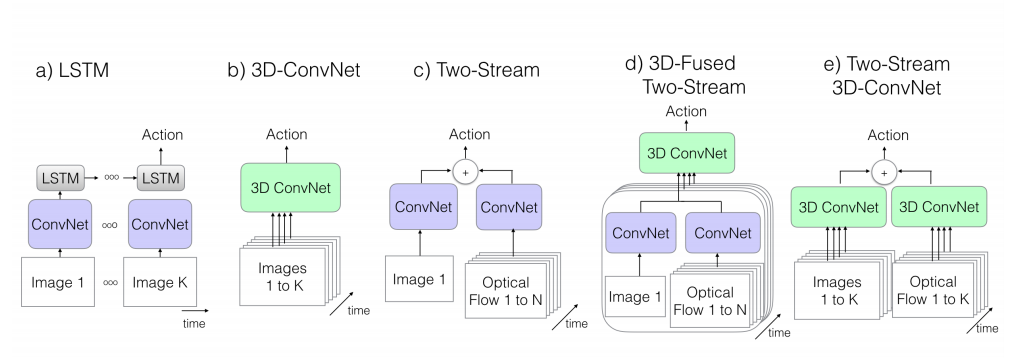
LRCN(Long-term Recurrent Convolutional Network)
https://arxiv.org/abs/1411.4389
关键贡献
- 基于之前的工作使用RNN来代替基于流的设计
- 用于视频表示的编码器架构的扩展
- 动作识别的端到端可训练架构
解释
在这之前有利用CNN对视频片段做特征提取,然后再用LSTM对时序的特征做最终分类,但效果不好。而LRCN是在卷积块(编码器)之后使用LSTM块(解码器)即端到端训练,同时也使用RGB和光流都作为输入,并将预测结果加权相加得到好的效果。

缺陷
- 将视频分为片段后,会导致某些片段没有标签对应的动作,从而干扰模型的效果
- 无法捕捉长期的时间信息
- 使用光流作为特征意味着需要分别计算流特征
基于上述缺陷,新的工作通过使用更低分辨率的视频和更长的视频片段(60帧)以实现更好的性能。
C3D
https://arxiv.org/pdf/1412.0767
关键贡献
- 利用三维卷积网络做特征提取器
- 广泛搜索最佳3D卷积内核和架构
- 使用反卷积层解释模型决策
解释

另外,作者使用了反卷积层来解释这样的设计,他们的发现是,在最初的几帧中,网络关注的是空间外观,并在随后的几帧中跟踪运动。

缺陷
- 长时间模型的建模依旧是个未解决的问题
- 过于庞大的网络在训练上计算过慢
Note:
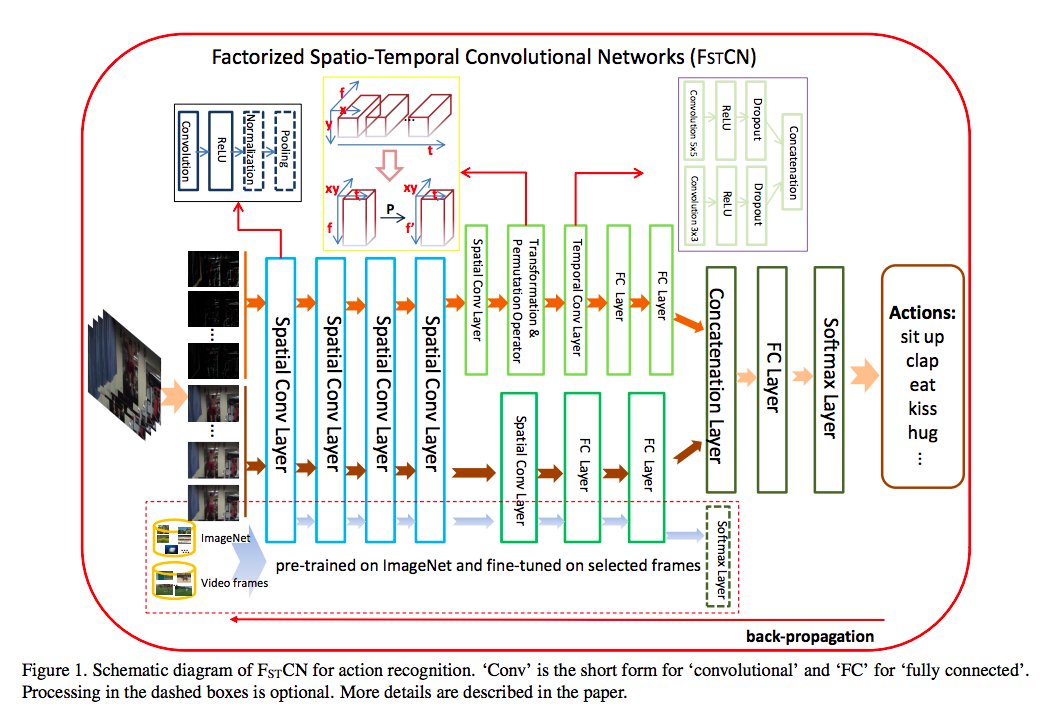
FSTCN,分解3D卷积网络,主要思路是将三维卷积分解为空间二维卷积,然后是时间一维卷积。将一维卷积放在二维卷积层之后,实现二维时域和信道维的卷积。
三维卷积+注意力机制
https://arxiv.org/abs/1502.08029
关键贡献
- 新颖的3D CNN-RNN编码器-解码器结构,可以捕捉局部时空信息
- 使用注意力机制来获取全局上下文
解释
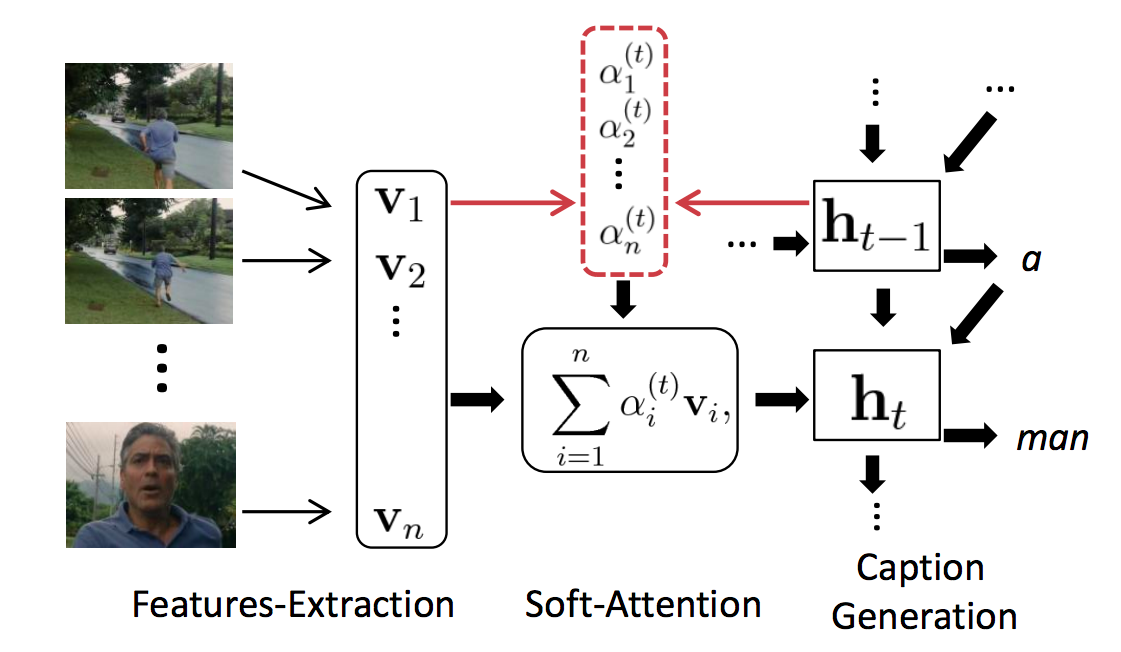
虽然这项工作与动作识别没有直接的关系,但在视频表征方面是具有里程碑意义的工作。本文采用三维CNN + LSTM作为视频描述任务的基础架构。在基础上,作者使用一个预先训练的3D CNN来提高效果。
算法
其设置与LRCN中描述的编码器-解码器架构几乎相同,但有两个不同之处:
- 并非单纯的使用了3D卷积做LSTM的特征向量输入。对于每一帧,先通过3D卷积获取feature maps,再通过2D卷积对其帧集获取feature maps集合。2D和3D CNN使用的是预先训练的,而不是像LRCN这样的端到端训练。
- 并非平均所有帧的时间向量。加权平均值的方法用于结合时间特征。在每个时间步上,根据LSTM输出来确定注意力权重。
TwoStreamFusion
https://arxiv.org/abs/1604.06573
关键贡献
- 通过更好的远距离损失的远距离时间建模
- 新颖的多层次融合架构
解释
在这个工作中,作者使用了基本的双流架构,并采用了两种新颖的方法,在提高性能的同时并不会带来任何参数的显著增加。
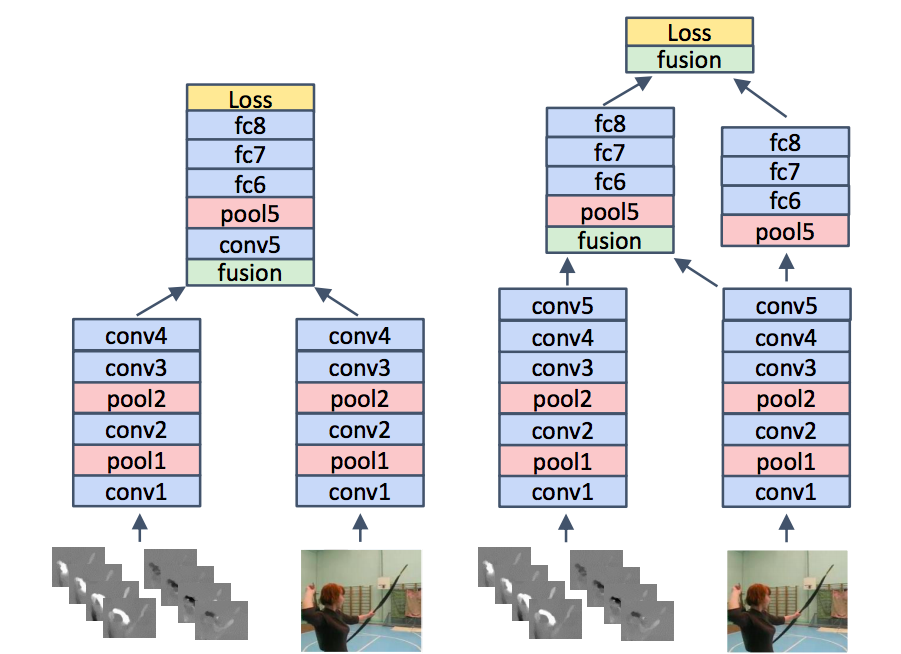
- 空间流和时间流的融合:以洗头和刷牙为例,空间网络可以捕捉视频中的空间相关性(判断头发还是牙齿),时间网络则可以捕捉到视频中每个空间位置的周期性运动。因此,将人脸特定区域的空间特征映射到相应区域的时间特征映射是非常重要的。为了达到同样的效果,网络需要在较早的水平上进行融合,使相同像素位置的响应处于对应状态,而不是在最后进行融合。
- 跨时间框架组合时间净输出,以便对长期依赖也进行建模。
算法
与双流架构基本一样,除了
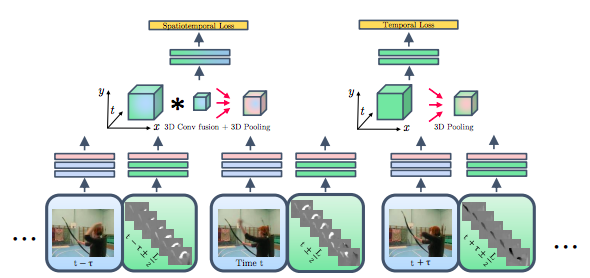
如下图所示,Conv_5层的输出均通过卷积层+池化层的方式融合,而此算法则在最后一层加了另一种融合,最后融合输出作为spatiotemporal loss。
时间融合采用跨时间叠加的时间网络输出,采用conv+pooling融合的方法计算时间损失
TSN
https://arxiv.org/abs/1608.00859
关键贡献
- 针对长期时间建模的有效解决方案
- 确定BN、dropout和预训练是一种有效的尝试
解释
与基本的双流架构有两个主要的不同:
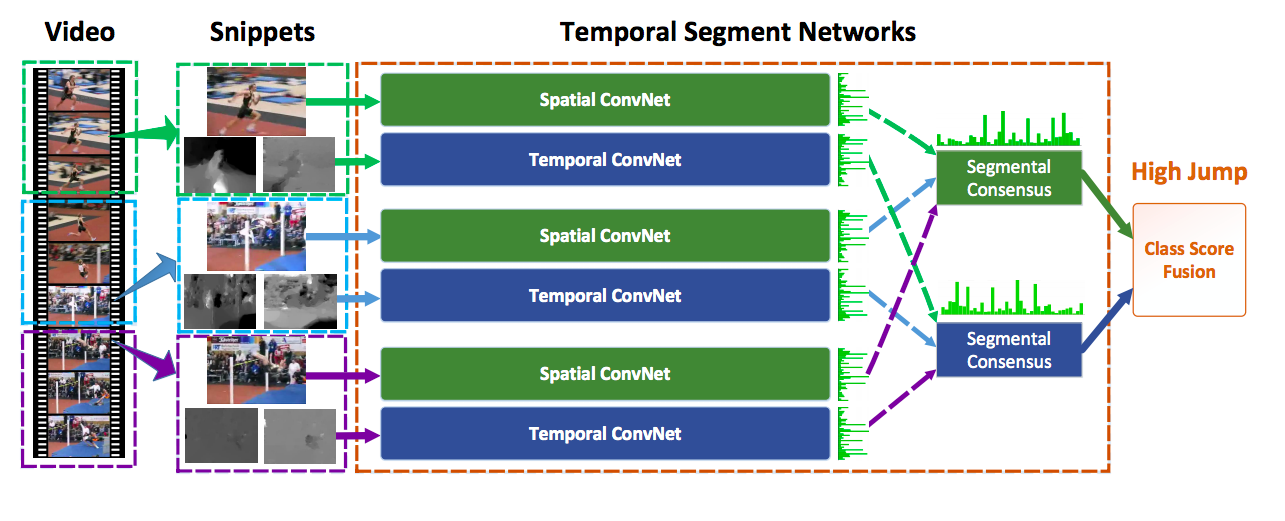
- 他们建议在整个视频中稀疏地采样片段,以更好地建模长期时间信号,而不是在整个视频中随机采样。
- 为了最终的预测,作者在视频层面探索了多种策略。最好的策略是
- 通过对片段平均,分别组合数十个时间和空间流(以及其他流,如果涉及其他输入模式)
- 对所有类融合最终的空间和时间得分使用加权平均和应用softmax。
该工作的另一个重要部分是解决过拟合问题(由于数据集规模较小),并演示使用现在流行的技术,如批处理规范化、Dropout和预训练来应对。作者还评估了两种新的光流输入模式,即弯曲光流和RGB差。
算法
在训练和预测过程中,将一段视频分成K段,每段时长相等。然后,从K个片段中随机抽取片段。其余的步骤仍然类似于上面提到的双流架构的更改。
ActionVLAD
https://arxiv.org/pdf/1704.02895.pdf
关键贡献
- 可学习的视频级聚合功能
- 具有视频级聚合特征的端到端可训练模型,以捕获长期依赖
解释
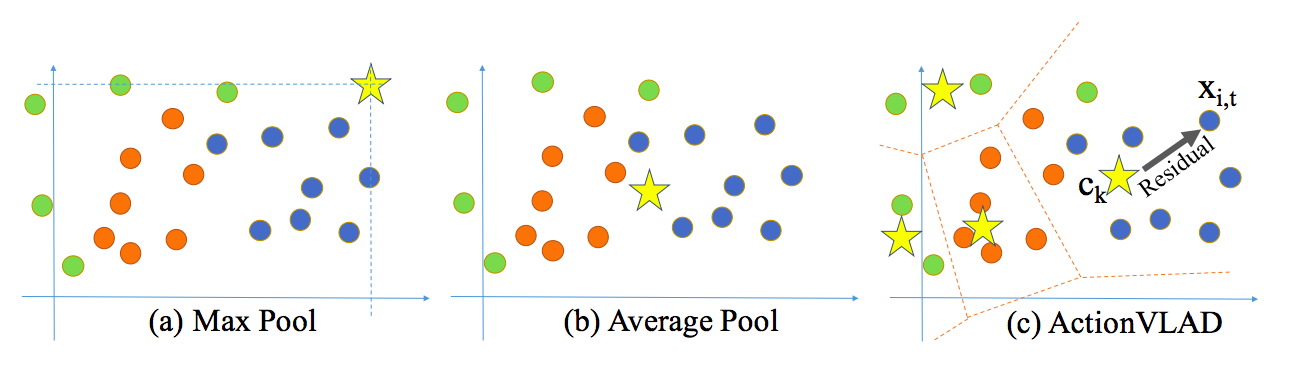
作者最显著的贡献是使用了可学习的特性聚合(VLAD),而不是使用maxpool或avgpool的普通聚合。聚合技术类似于视觉词汇。有多个基于锚点(比如\(c_1\), \(c_k\))的学习词汇,代表k个典型的动作(或子动作)相关的时空特征。两个流结构中的每个流的输出都按照k空间的动作词特征进行编码——每个特征都是输出与任何给定的空间或时间位置对应的锚点的差值。
(没看懂)
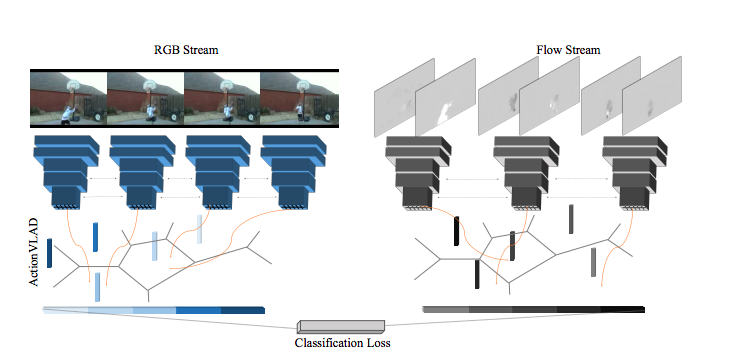
平均或最大池只作为一个描述符来表示整个点的分布,这对于表示由多个子动作组成的整个视频来说是次优的。相比之下,提出的视频聚合通过将描述符空间分割为k个单元并在每个单元内池化来表示具有多个子动作的描述符的整个分布。
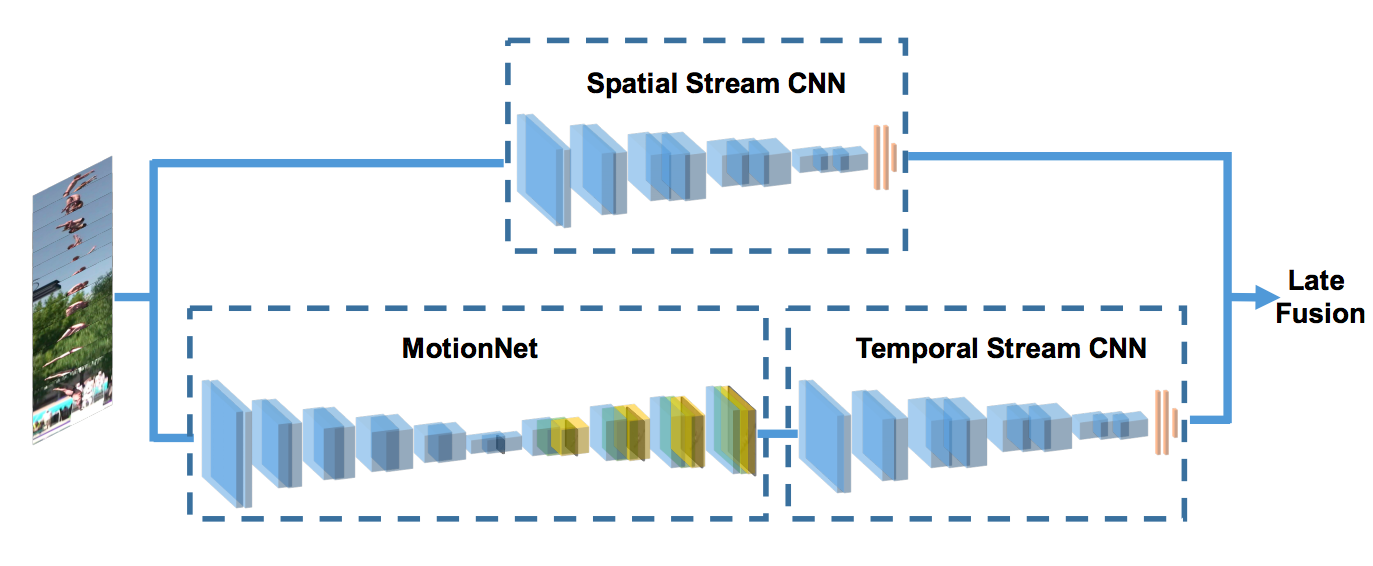
HiddenTwoStream
https://arxiv.org/abs/1704.00389
关键贡献
提出一种新颖的使用单独的网络实时生成光流输入的架构
解释
光流在双流架构的使用使得必须预先计算每个采样帧的光流,从而对存储和速度产生不利影响。这篇论文提出了一种使用无监督架构来生成光流的方法。
光流法可以被当成是一种图像重建问题。给定一对相邻的帧\(l_1、l_2\)作为输入,CNN生成一个流场\(V\),然后利用预测的流场\(V\)和\(l_2\),利用反翘曲将\(l_1\)重构为\(l_1^{'}\),使\(l_1\)与重构的差值最小。
算法
作者探索了多种策略和架构,在不太影响精度的前提下,以最大的帧数和最小的参数产生光流。最后的体系结构与前面提到的双流体系结构相同
- 时间流现在有堆叠在一般时间流架构的顶部的光流生成网络(MotionNet)。时间流的输入现在是后续帧而不是预处理的光流。
- 对于MotionNet的无监督训练,还有额外的多层次损失
I3D
https://arxiv.org/abs/1705.07750
关键贡献
- 利用预训练将基于3D的模型结合到两个流架构中
- Kinetics数据集用于未来的基准测试和改进的行动数据集的多样性
解释
作者不是使用单一的3D网络,而是在双流架构中为两个流使用两个不同的3D网络。此外,为了利用预训练的2D模型,作者在第三维中重复了2D预训练的权重。现在的空间流输入由时间维度上叠加的帧组成,而不是像基本的两种流结构那样由单个帧组成。
T3D
https://arxiv.org/abs/1711.08200
关键贡献
- 跨可变深度组合时间信息的架构
- 新颖的训练架构和技术,以监督2D预训练的网络转移到3D网络
解释
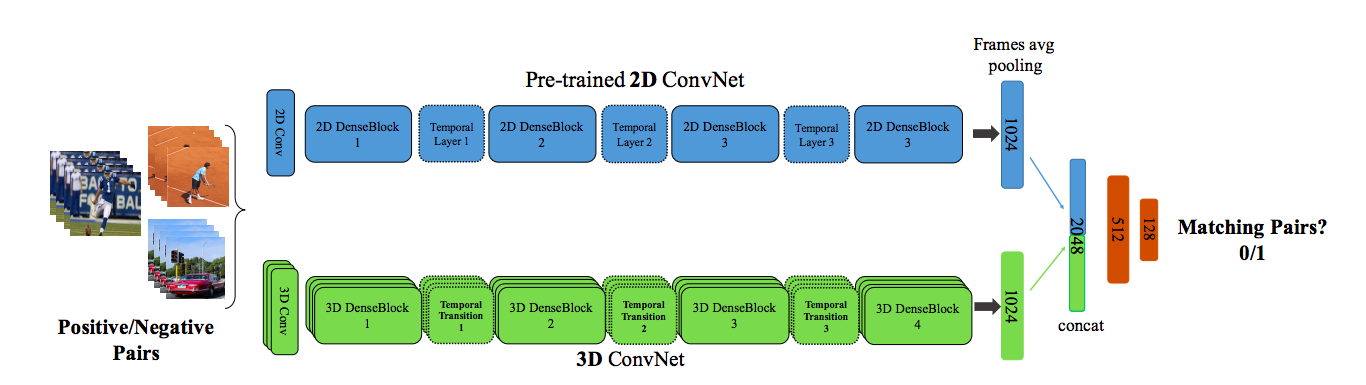
作者扩展了在I3D上完成的工作,但建议使用基于单一流3D DenseNet的架构,在密集块之后叠加多深度时间池化层(时间过渡层),以捕获不同的时间深度。多深度池化是通过池化不同时间大小的核来实现的。
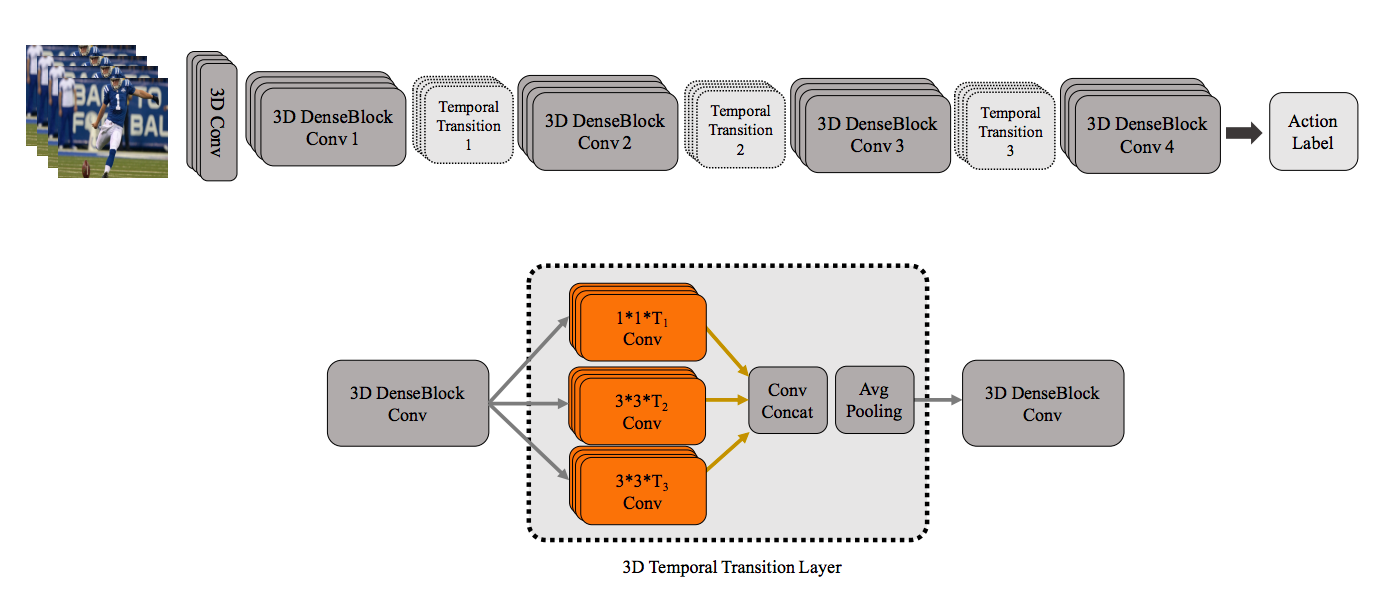
除上述内容外,作者还设计了一种新的技术,以在预先培训的2D Conv Nets和T3D中监督转移学习。2D预三角网和T3D都是从视频中呈现的框架和剪辑,其中剪辑和视频可能来自同一视频。该体系结构是基于相同的三角形来预测0/1的,并且预测的误差通过T3D NET进行了反向传播,以便有效地传输知识。